HomeSite is an HTML editor owned by Adobe Systems (formerly owned by Allaire and Macromedia).
HomeSite is a lightweight code environment designed for direct editing, or "hand coding," of HTML and
other website languages. It is available for the Windows platform.
More information about HomeSite can be found at:
http://www.adobe.com/products/homesite/
HomeSite regular expressions.
Information
none
Operating system used
Windows Vista Home Premium SP 1
Software prerequisites
HomeSite 5
Procedure
- You can use Homesite regular expressions when you select:
Menu: Search | Extended Find
or
Menu: Search | Extended Replace
Note: Do not forget to enable checkbox: Regular expressions.
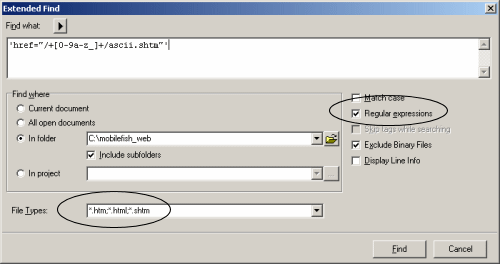
- The following rules govern one-character RegExp that match a single character:
- Special characters are: + * ? . [ ] ^ $ ( ) { } | \ &
- Any character that is not a special character matches itself.
- Use the keyboard (Tab, Enter) to match whitespace characters.
- The asterisk (*) matches the specified characters throughout the entire document.
- The carat (^) matches the beginning of the document.
- The dollar sign ($) matches the end of the document.
- A backslash (\) followed by any special character matches the literal character itself, that is, the backslash escapes the special character.
- The # and - characters must be escaped in expressions (## --) just as though they were special characters.
- A period (.) matches any character, including a new line. To match any character except a new line, use [^#chr(13)##chr(10)#], which excludes the HomeSite ASCII carriage return and line feed codes.
- A set of characters enclosed in brackets ([ ]) is a one-character RE that matches any of the characters in that set. For example, [akm] matches an a, k, or m. Note that if you want to include a closing square bracket (]) in square brackets, it must be the first character. Otherwise, it does not work even if you use \].
- Any regular expression can be followed by one of the following suffixes:
- {m,n} forces a match of m through n (inclusive) occurrences of the preceding regular expression
- {m,} forces a match of at least m occurrences of the preceding regular expression
The syntax {,n} is not allowed.
- A range of characters can be indicated with a dash. For example, [a-z] matches any lowercase letter. However, if the first character of the set is the caret (^), the RegExp matches any character except those in the set. It does not match the empty string. For example, [^akm] matches any character except a, k, or m. The caret loses its special meaning if it is not the first character of the set.
- All regular expressions can be made case-insensitive by substituting individual characters with character sets, for example, [Nn][Ii][Cc][Kk].
- You can use the following rules to build multicharacter regular expressions:
- Parentheses group parts of regular expressions together into grouped subexpressions that can be treated as a single unit. For example, (ha)+ matches one or more instances of "ha".
- A one-character regular expression or grouped subexpressions followed by an asterisk (*) matches zero or more occurrences of the regular expression. For example, [a-z]* matches zero or more lowercase characters.
- A one-character regular expression or grouped subexpressions followed by a plus (+) matches one or more occurrences of the regular expression. For example, [a-z]+ matches one or more lowercase characters.
- A one-character regular expression or grouped subexpressions followed by a question mark (?) matches zero or one occurrences of the regular expression. For example, xy?z matches either "xyz" or "xz".
- The concatenation of regular expressions creates a regular expression that matches the corresponding concatenation of strings. For example, [A-Z][a-z]* matches any capitalized word.
- The OR character (|) allows a choice between two regular expressions. For example, jell(y|ies) matches either "jelly" or "jellies".
- Braces ({}) are used to indicate a range of occurrences of a regular expression, in the form {m, n} where m is a positive integer equal to or greater than zero indicating the start of the range and n is equal to or greater than m, indicating the end of the range. For example, (ba){0,3} matches up to three pairs of the expression "ba".
- HomeSite supports back referencing, which allows you to match text in previously matched sets of parentheses. You can use a slash followed by a digit n (\n) to refer to the nth parenthesized subexpression.
One example of how you can use back references is searching for doubled words, for example, to find instances of "is is" or "the " in text. The following example shows the syntax you use for back referencing in regular expressions:
("There is is coffee in the kitchen", "([A-Za-z]+)[ ]+\1","*","ALL")
This code searches for words that are all letters ([A-Za-z]+) followed by one or more spaces [ ]+ followed by the first matched subexpression in parentheses. The parser detects the two occurrences of is as well as the two occurrences of the and replaces them with an asterisk, resulting in the following text:
There * coffee in * kitchen
- You can anchor all or part of a regular expression to either the beginning or end of the string being searched:
- If a caret (^) is at the beginning of a subexpression, the matched string must be at the beginning of the string being searched.
- If a dollar sign ($) is at the end of a subexpression, the matched string must be at the end of the string being searched.
- The following table shows some regular expressions and describes what they match:
|
| [\?&]value= | A URL parameter value in a URL |
| [A-Z]:(\\[A-Z0-9_]+)+ | An uppercase DOS/Windows full path that is not the root of a drive, and that has only letters, numbers, and underscores in its text |
| (\+|-)?[1-9][0-9]* | An integer that does not begin with a zero and has an optional sign |
| (\+|-)?[1-9][0-9]*(\.[0-9]*)? | A real number |
| (\+|-)?[1-9]\.[0-9]*E(\+|-)?[0-9]+ | A real number in engineering notation |
| a{2,4} | Two to four occurrences of "a": aa, aaa, aaaa |
| (ba){3,} | At least three "ba" pairs: bababa, babababa, ... |
| (" [A-Za-z] "){2,} | At least two occurrences of the same word |
| <a href="/+[0-9a-z_]+/ascii.html" id="NavSubTitle"> | Finds: <a href="/developer/ascii.html" id="NavSubTitle"> |
| ([0-9]+[ ][a-zA-z]{3,}) | Finds: 5 Jan, 10 Mar, 15 Dec |
| <img[ ]+ | Finds: <img (followed by 1 or mores spaces) |
| <img([ ]+[a-z]+[ ]*=[ ]*["a-zA-Z0-9:_\\/\.]+)+[ ]*> | Finds: <img src="/images/space.gif" width="156" height="1" > |
| <([^>]+)> | Finds: all tags starting with < and ends with > including all attributes |
| <[A-Z]+> |
Finds: all tags starting with < and ends with > with no attributes.
For example: <table>.
Note: If the regular expression must match the case, enable checkbox: Match case
|
- The following table shows some regular expressions for Extended Replace:
|
|
([a-zA-Z]{3,})[ ]([0-9])
|
\1tober \2, 2003.
|
To replace Oct 5 with October 5, 2003.
The \1 represents the first subexpression in parenthesis and the \2 represents the second subexpression in parenthesis
|
|
<img([^>]+)>
|
<img\1 />
|
To replace the closing > with />
Note: When this RE has been executed, make sure
to replace the following:
Remove space:
/> </td> into /></td>
/> <br /> into /><br />
|
|
(name)="([^"]+)"
|
\1="\2" id="\2"
|
If name="xxx" is found replace with
name="xxx" id="xxx".
Note: Add a space after id="\2"
|
|
<(a[ ]+href[ ]*=[ ]*"[^<]+")
|
<\1 onfocus="this.blur()"
|
Replace <a href=".." with
<a href=".." onfocus="this.blur()"
|
|
<a name="([.a-zA-Z0-9_]+)" id="([a-zA-Z0-9_]+)">([.a-zA-Z0-9_ ]+)
|
<a name="\1" id="\1"><span id="\2">\3</span>
|
Replace:
<a name="Text" id="CSSText">Title</a>
with
<a name="Text" id="Text"><span id="CSSText">Title</span></a>
|
(href[ ]*=[ ]*["|'][ ]*http(|s):
//([A-Za-z0-9-_%&?.=#,~@+]+)/
?[A-Za-z0-9-_%&?/.=#,~@:+]*
[ ]*["|'])
|
\1 onclick="javascript:
mytracker(this.href);"
|
Replace:
<a href="http://www.example.com"
>test</a>
with
<a href="http://www.example.com"
onclick="javascript:mytracker(this.href);">
test</a>
|
<span[ ]+class="Title"[ ]*>
([a-zA-Z0-9 -.+=:"'&/_\(\)]+)</span>
|
<h1 class="Title">\1</h1>
|
Replace:
<span class="Title">Hello</span>
with
<h1 class="Title">Hello</h1>
|
|
|