Java char type.
Information
The Unicode consortium, has mapped every character to a unique number called a code point,
for example character € has the code point U+20AC.
The U+ means "Unicode" and the numbers are hexadecimal.
Unicode range U+0000 to U+007F, has the same values as the equivalent ASCII characters.
Unicode range U+00A0 to U+00FF, has the same values as the equivalent ISO-8895-1 Latin-1 characters.
In Java characters are encoded using the UTF-16 (Unicode Transformation Format) encoding scheme whereby the code points are represented by 16 bits.
The set of characters from U+0000 to U+FFFF, that fits in two bytes, is referred to as the Basic Multilingual Plane (BMP).
For example:
The character ɤ (U+0264) is a character in the Basic Multilingual Plane (see: Unicode character map or Unicode Code Charts) and in Java it is stored in two bytes:
0x02 0x64 (big-endian)
Unicode has however defined more characters than fit into two bytes (max 65,536).
The Unicode standard has been extended to allow up to 1,112,064 characters. Those characters that go beyond the
original 16-bit limit are called supplementary characters and the code points are in the range U+10000 to U+10FFFF.
To still represent the supplementary characters in the UTF-16 encoding scheme, the following solution is used:
Unicode has allocated 2048 code points as surrogate code points and Unicode will not assign any characters to these code points.
These code points are divided into high-surrogates (U+D800 to U+DBFF) and low-surrogates (U+DC00 to U+DFFF) points.
Example 1:
The character 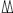 (U+102B7) is a supplementary character.
To encode this character in UTF-16: (U+102B7) is a supplementary character.
To encode this character in UTF-16:
- First subtract 0x102B7 with 0x10000, result: 0x002B7
- In binary form, the result 0x002B7 looks like: 0000 0000 0010 1011 0111
- Split the result into two 10-bits, result: 0000000000 1010110111 (0x000 0x2B7)
- Add 1101100000000000 (0xD800) to the high 10 bits 0000000000 (0x000), result:
1101100000000000 (0xD800)
- Add 1101110000000000 (0xDC00) to the low 10 bits 1010110111 (0x2B7), result:
1101111010110111 (0xDEB7)
- The character is represented by surrogate pairs (0xD800) and (0xDEB7) and are stored in 4 bytes:
0xD8 0x00 0xDE 0xB7 (big-endian)
Example 2:
The character 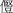 (U+2040A) is a supplementary character.
To encode this character in UTF-16: (U+2040A) is a supplementary character.
To encode this character in UTF-16:
- First subtract 0x2040A with 0x10000, result: 0x1040A
- In binary form, the result 0x1040A looks like: 0001 0000 0100 0000 1010
- Split the result into two 10-bits, result: 0001000001 0000001010 (0x041 0x00A)
- Add 1101100000000000 (0xD800) to the high 10 bits 0001000001 (0x041), result:
1101100001000001 (0xD841)
- Add 1101110000000000 (0xDC00) to the low 10 bits 0000001010 (0x00A), result:
1101110000001010 (0xDC0A)
- The character is represented by surrogate pairs (0xD841) and (0xDC0A) and are stored in 4 bytes:
0xD8 0x41 0xDC 0x0A (big-endian)
The steps shown in example 1 and 2 can be represented by a formula to calculate the high and low surrogate pair:
high surrogate pair = 0xD7C0 + (code point >> 10)
low surrogate pair = 0xDC00 + (code point & 0x3FF)
For example:
code point = U+2F97A (character 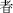 ) )
high surrogate pair = 0xD7C0 + (0x2F97A >> 10) = 0xD87E
low surrogate pair = 0xDC00 + (0x2F97A & 0x3FF) = 0xDD7A
Char values (Basic Multilingual Plane (BMP) are stored in 2 bytes.
The char value range is: 216 = 65536
Char numbers ranges from: >=0 and <=65536
For example:
0x0000 0x0000 = 0
0x0000 0x0001 = 1
0xFFFF 0xFFFF = 65536
During arithmetic operations the JVM always convert the char value into an int.
|